API串接過程中,並非每次都能順利進行,尤其是當問題來自提供API的那一方時,常見的問題如下:
- CORS問題
- 資料數量過大
- 資料格式為json以外的文字檔案(.txt,.csv,.xml…)
我提供幾個自己的經驗,做為遇到以上問題時的基本排除原則,具體做法還是要看API的狀況來決定。
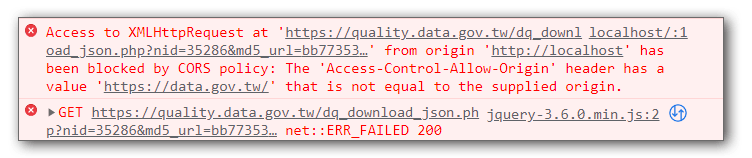
CORS問題
CORS的問題來自於同源政策引起的,通常是因為提供資料的伺服器端沒有開放非同源存取所造成的,最快的解決方式是透過本地端的伺服器,使用curl或同性質的指令去摸擬http請求,藉此取得資料後再傳遞給前端js程式來使用
1 | $.get("...url...",(data)=>{ |
在php中,如果要取得的資料不需要太複雜的參數傳送,只需要 get 方法就可以取得的話,可以使用 file_get_contents() 來快速取得資料
1 | echo file_get_contents($url); |
如果是要使用POST或需要較複雜的存取行為,或者有效率考量的話,則使用 curl 指令會比較適合
1 | // 初始化 CURL |
修改前端js的網址為同源的php檔案,即可取得資料
1 | $.get("get_data.php",(data)=>{ |
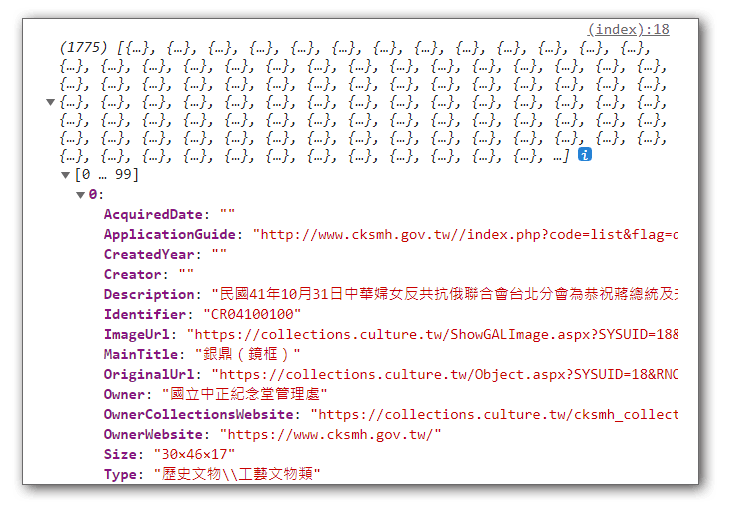
資料數量過大
以上例來說,資料量有1700多筆,雖然透過網路取得的速度很快,但是在瀏灠器使用js處理大量資料時,還是有可能會造成效能的問題,有幾個解決方向:
- 查看對方的API規格,是否有提供數量限制的參數,如果有的話,則可以透過傳遞參數的方式來限制每次取得的數量
- 先在本地端使用後端程式語言處理過資料,縮小資料量或規範資料的內容,再丟回給前端
- 在本地端使用後端程式語言取得資料後,將資料存入資料庫,再自行撰寫本地端的api供前端使用
這裏解說存入資料庫的做法:
先依照資料的欄位在地本端建立資料庫及資料表: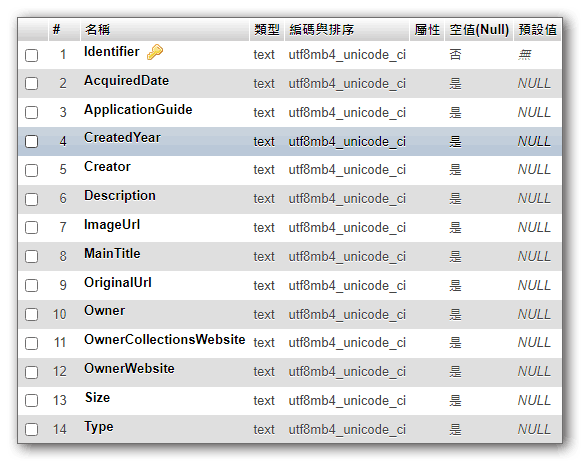
在本地端先取得資料,如果確認對方提供的資料格式是JSON,可以使用 json_decode() 來解析回傳資料
1 | //利用 file_get_contents() 函式抓回資料,資料會以字串的型式回傳 |
我們發現json_decode後中,陣列中的資料以stdClass的型式存在陣列中,這表示每一項資料都是以類物件的方式被轉換出來,所以我們要以物件的方式來存取資料內容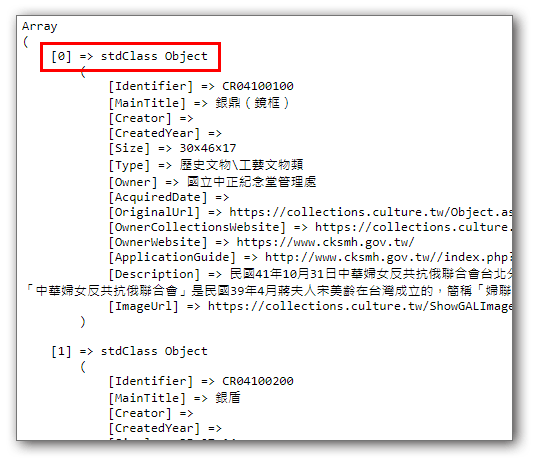
開始撰寫寫入資料表的語法(再次強調,依據資料的不同,處理方式可能會有極大的差異):
1 | $dsn="mysql:host=localhost;charset=utf8;dbname=culture"; |
執行該php程式後,即可在取得資料後將資料寫入本地端的資料表中: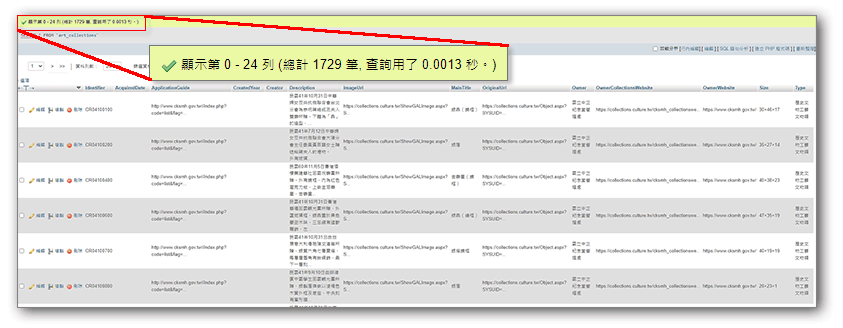
撰寫本地端的api程式,可以自行設定是否要代入參數來取得資料,或是在後端設定好分頁資訊,讓前端存取
1 | $dsn="mysql:host=localhost;charset=utf8;dbname=culture"; |
前端改以本地端的api程式來取得資料:
1 | $.get("art_collections.php",(data)=>{ |
改以本地端資料表的方式來取得資料,則資料量和呈現的方式,都可以在本地端自行決定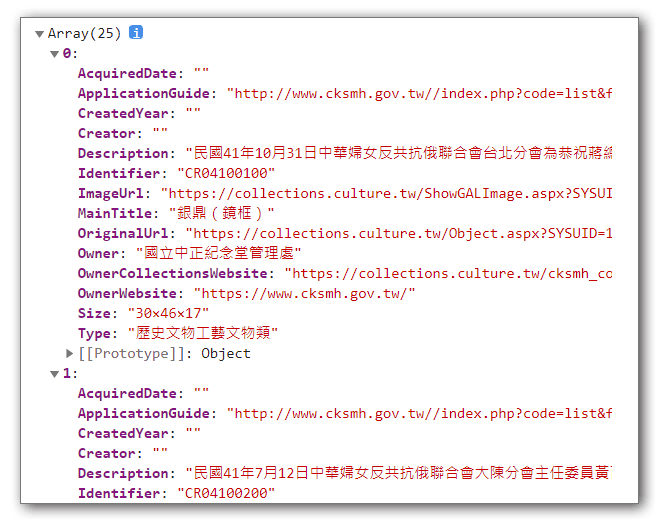
資料格式非JSON
如果想串接的資料不是回覆json或xml,或者該資料僅有一個獨立的檔案,沒有參數可供調整回傳的內容,這樣其實已經不太算是串接api了,反而比較接近爬資料的方式。
爬蟲和串API的最大差異在於是否提供參數做為資料的區隔,以 中央氣象局開放資料平臺之資料擷取API為例,每一項api的網址點開後,都還有各種詳細的參數可供選擇,透過傳遞不同的參數,同一個API網址可以獲得不同的資料內容。
如果對像資料只是一個資料檔案,而且也不是json格式的資料,那麼可以採取的對應做法就是以檔案處理的方式來進行,也就是先把檔案抓下來本地端,再依照後端程式語言或前端程式語言中的檔案處理機制對檔案進行 解析 ,再看是要存入資料表還是做成json的格式回應給前端,這邊以臺北市立動物園_動物資料為例,該資料僅提供 .csv 版本的資料格式,同時有 CORS 的問題無法直接以JS取得。

而 .csv 格式有個問題是資料中僅有第一列有標題,其它資料並沒有像 json 一樣的 key-value 格式

因此我們採用後端PHP程式來把資料抓下來,並將資料先存在本地端形成一個檔案,接著我們依照檔案的格式,使用php程式重新整理每一筆資料為json的資料格式,最後再丟給前端。
1 | //利用 file_get_contents() 函式抓回資料,資料會以字串的型式回傳 |
可以在命令列直接執行這個檔案,執行完畢後即可在目錄中看到抓下來的 .csv 檔案
另外撰寫一支PHP程式用來處理這個抓下來的檔案,作為提供給前端呼叫之用,這邊要處理的重點在於幫每一筆資料加上對應的鍵名,以形成一個 json 的格式,前端才能進行處理,由於檔案格式為 .csv 因此我們使用php函式中的 fgetcsv() 來對每一筆資料做解析
1 | //以讀取模式開啟檔案 |
處理成功的資料會以PHP陣列中的 key-value 方式呈現,再使用 json_encode($array) 把陣列轉成 json 格式傳給前端即可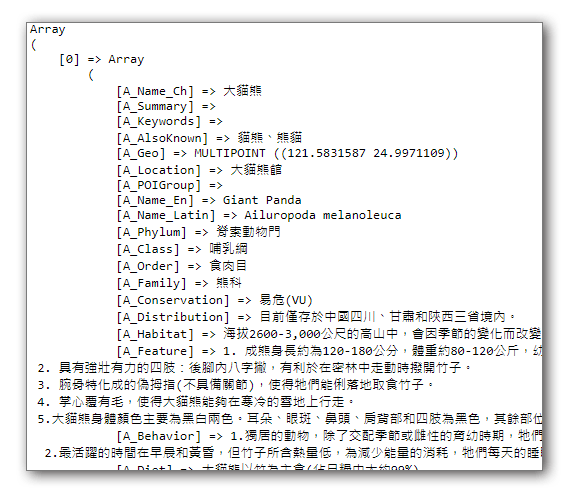
1 | $.get("animal.php",(data)=>{ |

補充
這類非json格式的資料,通常的處理方式會傾向抓下來後存到資料庫,再自行撰寫api來使用,但隨之而來的問題是我們不會知道對方的資料何時會更新,因此配套措施是利用作業系統的定時執行功能,每隔一周或一個月就自動去重新抓一次資料並更新資料庫。